Turn Detection
In conversational AI, timing is everything. Traditional voice agents rely on simple silence-based timers (Voice Activity Detection or VAD) to guess when a user has finished speaking. This often leads to awkward interruptions or unnatural pauses.
Turn detection solves this by understanding the meaning of what the user said, not just the silence after it, so your agent knows when to respond instantly and when to keep listening.
From Silence to Speech Understanding
Semantic turn detection shifts from basic audio analysis to Natural Language Understanding (NLU), letting your agent tell the difference between a user who is truly finished and one who is just pausing to think.
| Traditional VAD (Silence-Based) | Semantic Turn Detection |
|---|---|
| Listens for silence. | Understands words and context. |
| Relies on a fixed timer (e.g., 800ms). | Uses a transformer model to predict intent. |
| Often interrupts or lags. | Knows when to wait and when to respond instantly. |
| Struggles with natural pauses and filler words. | Distinguishes between a brief pause and a true endpoint. |
VideoSDK offers two ways to add semantic turn detection to a cascade pipeline:
- Echo (Inference): server-hosted, lowest-setup option. Choose
echo-smallfor speed orecho-largefor accuracy. - TurnSense: runs in the cloud or fully on-device.
In every case, VAD detects that speech is happening; the turn detector decides when the turn is over.
Echo Turn Detection (Inference)
Echo is VideoSDK's recommended turn detector for natural, real-time conversations. It is a multilingual model that understands when a speaker has actually finished talking, with support for 12 languages in total, spanning both Indian and international languages. Echo comes in two variants so you can tune for your use case: echo-small for the lowest latency and echo-large for the highest accuracy.
Echo is server-hosted on the VideoSDK Inference Gateway and exposed through the TurnV2 class, so there is no model to download or run on your machine. Authentication uses the VIDEOSDK_AUTH_TOKEN environment variable.
How It Works
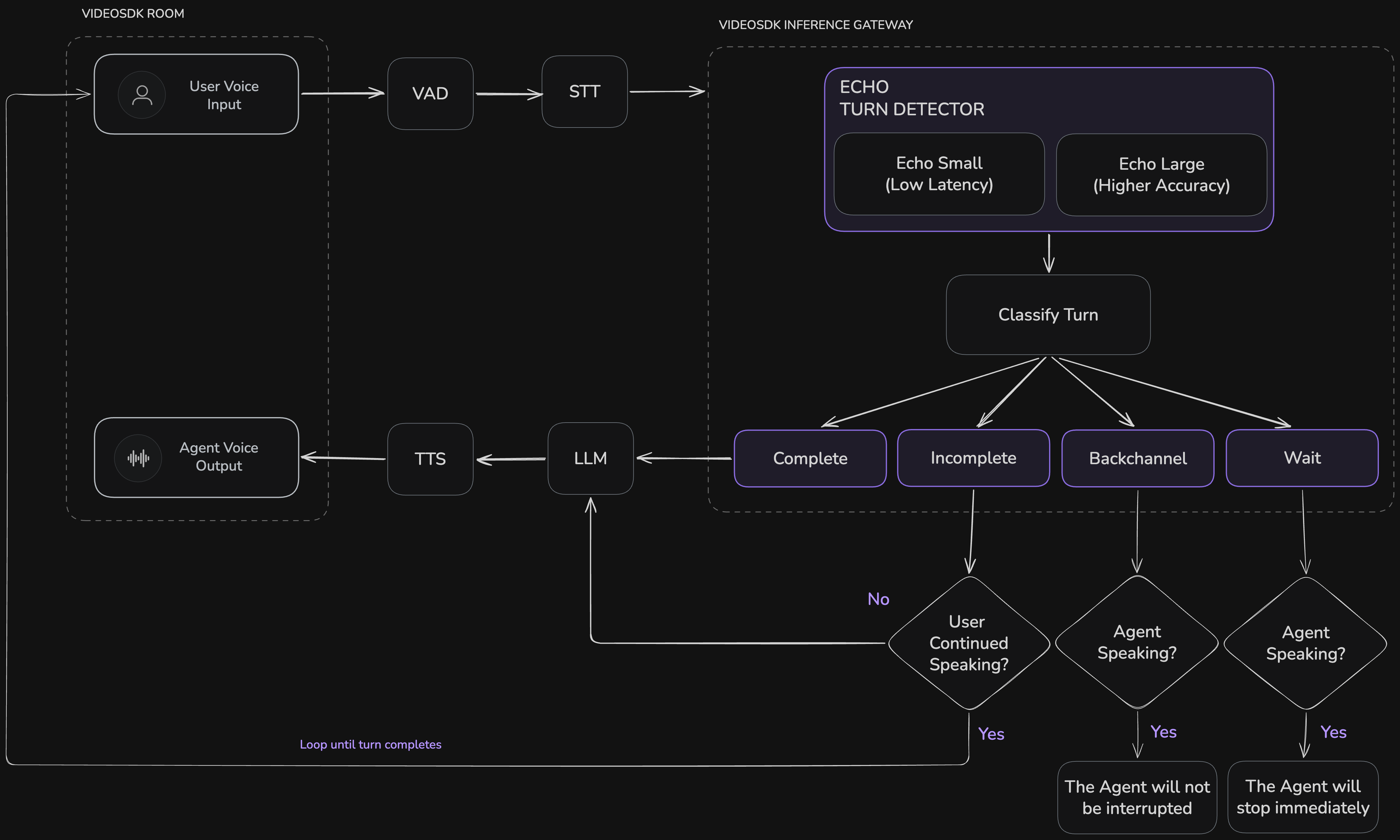
As the user speaks, VAD detects the speech and STT produces a transcript. After each user utterance, the latest transcript is sent to the Inference Gateway, where the selected Echo model (echo-small or echo-large) classifies the turn into one of four states:
| State | Meaning |
|---|---|
Complete | The user has finished their turn. |
Incomplete | The user is still mid-sentence or not finished yet. |
Backchannel | A short acknowledgement (e.g. "uh-huh", "okay okay"). |
Wait | The user wants the agent to hold (e.g. "wait a minute", "hold on"). |
Models
Both models share the same four-state classification; they differ only in the latency/accuracy trade-off:
| Provider | Model Name | Model ID |
|---|---|---|
| VideoSDK | Echo Small | echo-small |
| VideoSDK | Echo Large | echo-large |
TurnV2.echo_small()
- The default, lowest-latency model optimized for the fastest possible turn detection.
- Best when responsiveness matters most.
TurnV2.echo_large()
- A higher-accuracy model that trades a little latency for better classification.
- Best when accuracy matters more than raw speed.
Use echo-small for the lowest latency (the default), or echo-large when accuracy matters more than raw speed.
Supported Languages
Both echo-small and echo-large support the following languages:
| # | Language | # | Language |
|---|---|---|---|
| 1 | English | 7 | Urdu |
| 2 | Hindi | 8 | Bengali |
| 3 | Gujarati | 9 | French |
| 4 | Marathi | 10 | German |
| 5 | Tamil | 11 | Italian |
| 6 | Telugu | 12 | Spanish |
Usage
echo-large and echo-small models are supported from videosdk-agents>=1.0.18.
Set your auth token, then import and configure TurnV2:
pip install "videosdk-agents>=1.0.18"
VIDEOSDK_AUTH_TOKEN="your-videosdk-auth-token"
from videosdk.agents.inference import TurnV2
# Fastest, lowest latency (default)
turn_detector = TurnV2.echo_small()
# Higher accuracy
turn_detector = TurnV2.echo_large()
Performance
Benchmarked on the TURNS2K dataset against a leading third-party turn-detection model, referred to here as Baseline. Each sample is labeled Complete (the user has finished speaking) or Incomplete (the user is still speaking).
| Metric | Echo-Small | Echo-Large | Baseline |
|---|---|---|---|
| Accuracy | 93.60% | 96.20% | 61.13% |
| Recall (Complete) | 97.31% | 96.50% | 32.83% |
| Specificity | 88.91% | 95.81% | 96.83% |
| F1 Score (Complete) | 0.9443 | 0.9659 | 0.4851 |
Echo-Large
On 2,000 English conversational samples, Echo-Large achieved 96.2% accuracy in detecting whether a speaker had finished their turn, substantially outperforming the Baseline under the same conditions. The largest difference was in turn-completion detection: Echo-Large correctly identified 96.5% of completed turns versus 32.8% for the Baseline, resulting in far fewer missed responses.
For every 100 times a user finished speaking, Echo-Large responded correctly approximately 97 times, missing only ~3.5 turn completions; the Baseline responded correctly about 33 times.
Echo-Small
Echo-Small is optimized for responsive voice interactions where recognizing completed speech quickly is critical.
For every 100 times a user finished speaking, Echo-Small responded correctly 97.3 times versus 32.8 for the Baseline, about 25× fewer missed turn endings in this benchmark. Echo-Small is designed for applications where fast conversational turn-taking is a priority, while maintaining strong overall classification performance.
Results are measured on the benchmark dataset described above, on samples labeled Complete or Incomplete. Performance may vary depending on language, deployment configuration, user behavior, and application requirements.
TurnSense
TurnSense (SmolLM2-135M, English) is an alternative turn detector exposed through the TurnDetector class. It can run through the Inference Gateway or fully on-device.
| Backend | Class | Languages | Deployment |
|---|---|---|---|
| TurnSense (SmolLM2-135M) | TurnDetector | English | Cloud or local |
- Inference
- Local Models
Import the turn detector class from videosdk.agents.inference for HTTP-based EOU detection through the VideoSDK Inference Gateway; no local model download required.
from videosdk.agents.inference import TurnDetector
# TurnSense / SmolLM2-135M (English)
turn_detector = TurnDetector(threshold=0.7)
Cloud turn detection requires VIDEOSDK_AUTH_TOKEN. See Authentication and Tokens.
Install the turn-detector plugin and run the model on-device. The model downloads on first use; no network calls during inference.
pip install "videosdk-plugins-turn-detector"
from videosdk.agents.plugins import TurnDetector
# TurnSense (SmolLM2-135M, English)
turn_detector = TurnDetector(threshold=0.7)
For plugin-specific setup, see Turn Detector.
Got a Question? ![]() Ask us on discord
Ask us on discord

