Turn Detection and Voice Activity Detection
In conversational AI, timing is everything. Traditional voice agents rely on simple silence-based timers (Voice Activity Detection or VAD) to guess when a user has finished speaking. This often leads to awkward interruptions or unnatural pauses.
To solve this, VideoSDK created Namo-v1: an open-source, high-performance turn-detection model that understands the meaning of the conversation, not just the silence.
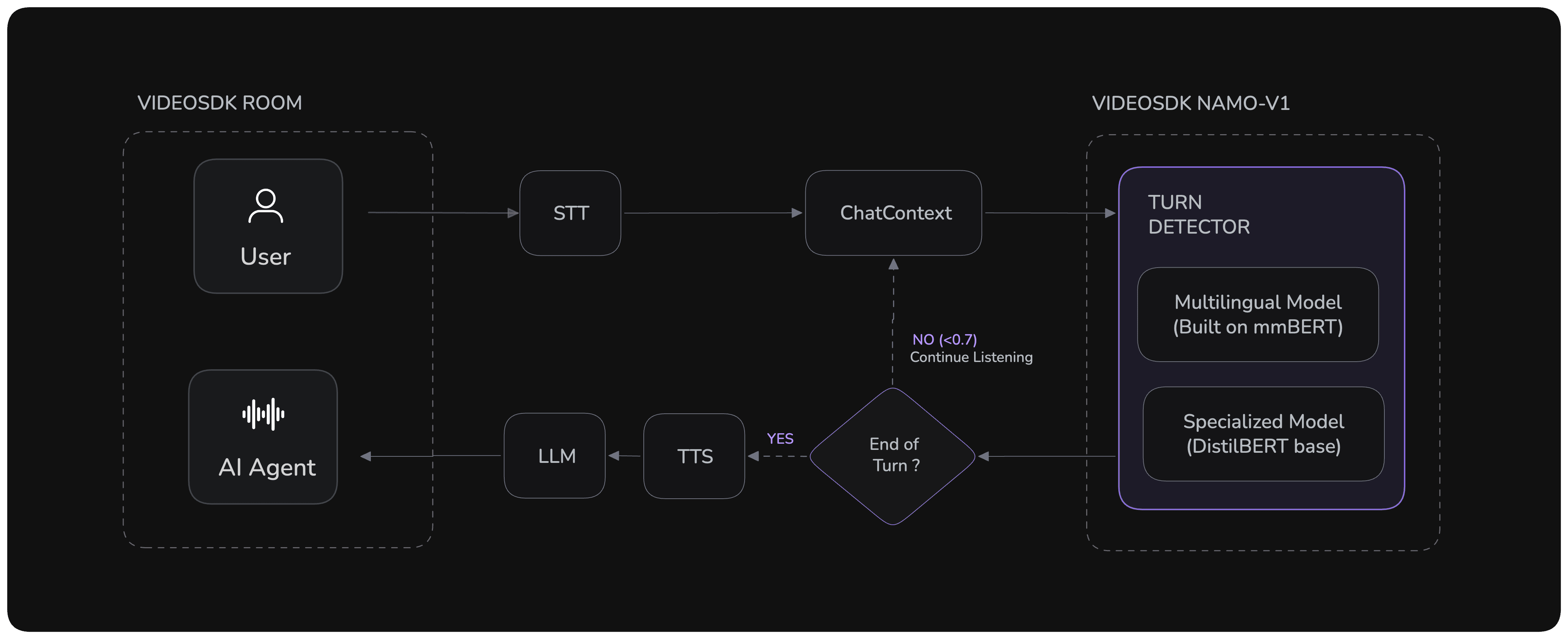
From Silence Detection to Speech Understanding
Namo shifts from basic audio analysis to sophisticated Natural Language Understanding (NLU), allowing your agent to know when a user is truly finished speaking versus just pausing to think.
| Traditional VAD (Silence-Based) | Namo Turn Detector (Semantic-Based) |
|---|---|
| Listens for silence. | Understands words and context. |
| Relies on a fixed timer (e.g., 800ms). | Uses a transformer model to predict intent. |
| Often interrupts or lags. | Knows when to wait and when to respond instantly. |
| Struggles with natural pauses and filler words. | Distinguishes between a brief pause and a true endpoint. |
This semantic understanding enables AI agents to respond quicker and more naturally, creating a fluid, human-like conversational experience.
For a deep dive into Namo's architecture, performance benchmarks, and how to use it as a standalone model, check out the dedicated Namo Turn Detector plugin page.
Implementation
For the most robust setup, use VAD together with an inference-based turn detector. VAD acts as a basic speech detector, while the turn detector intelligently decides if the turn is over.
1. Voice Activity Detection (VAD)
First, configure VAD to detect the presence of speech. This helps manage interruptions and acts as a first-pass filter.
from videosdk.agents.plugins import SileroVAD
# Configure VAD to detect speech activity
vad = SileroVAD(
threshold=0.5, # Sensitivity to speech (0.3-0.8)
min_speech_duration=0.1, # Ignore very brief sounds
min_silence_duration=0.75 # Wait time before considering speech ended
)
2. Turn Detection Options (Inference + Local)
In cascade mode, pair VAD with an inference-based turn detector for End-of-Utterance (EOU) detection. VAD detects when speech is present; the turn detector determines when the user has finished speaking based on transcript content.
| Backend | Class | Languages | Deployment |
|---|---|---|---|
| Namo v1 | NamoTurnDetectorV1 | Multilingual (23) | Cloud or local |
| TurnSense (SmolLM2-135M) | TurnDetector | English | Cloud or local |
| VideoSDK BERT | VideoSDKTurnDetector | English | Cloud or local |
- Inference
- Local Models
Import the turn detector classes from videosdk.agents.inference for HTTP-based EOU detection through the VideoSDK Inference Gateway - no local model download required.
from videosdk.agents.inference import NamoTurnDetectorV1, TurnDetector, VideoSDKTurnDetector
# Namo Turn Detector v1 (multilingual)
turn_detector = NamoTurnDetectorV1(language="en", threshold=0.7)
# TurnSense / SmolLM2-135M (English)
turn_detector = TurnDetector(threshold=0.7)
# VideoSDK BERT-based detector (English)
turn_detector = VideoSDKTurnDetector(threshold=0.7)
Cloud turn detection requires VIDEOSDK_AUTH_TOKEN. See Authentication and Tokens.
Install the turn-detector plugin and run models on-device. Models download on first use; no network calls during inference.
pip install "videosdk-plugins-turn-detector"
from videosdk.agents.plugins import TurnDetector, VideoSDKTurnDetector, NamoTurnDetectorV1
# TurnSense (SmolLM2-135M, English)
turn_detector = TurnDetector(threshold=0.7)
# VideoSDK BERT-based detector (English)
turn_detector = VideoSDKTurnDetector(threshold=0.7)
# Namo Turn Detector v1 (multilingual)
turn_detector = NamoTurnDetectorV1(threshold=0.7, language="en")
For plugin-specific setup, see Turn Detector and Namo Turn Detector.
Namo Language Options
Namo supports a single multilingual model or per-language models for better accuracy:
Multilingual Model
If your agent needs to support multiple languages, use the default multilingual model. It's a single, powerful model that works across more than 20 languages.
from videosdk.agents.plugins import NamoTurnDetectorV1, pre_download_namo_turn_v1_model
# Pre-download the multilingual model to avoid runtime delays
pre_download_namo_turn_v1_model()
# Initialize the multilingual Turn Detector
turn_detector = NamoTurnDetectorV1(
threshold=0.7 # Confidence level for triggering a response
)
The table below lists all supported languages with their performance metrics and language codes.
| Language | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| 🇸🇦 Arabic | 0.849 | 0.7965 | 0.9439 | 0.8639 |
| 🇮🇳 Bengali | 0.794 | 0.7874 | 0.7939 | 0.7907 |
| 🇨🇳 Chinese | 0.9164 | 0.8859 | 0.9608 | 0.9219 |
| Show 19 More... | ||||
Language-Specific Models
For maximum performance and accuracy in a single language, use a specialized model. These models are faster and have a smaller memory footprint.
from videosdk.agents.plugins import NamoTurnDetectorV1, pre_download_namo_turn_v1_model
# Pre-download a specific language model (e.g., German)
pre_download_namo_turn_v1_model(language="de")
# Initialize the Turn Detector for German
turn_detector = NamoTurnDetectorV1(
language="de",
threshold=0.7
)
| Language | Code | Model Link | Accuracy |
|---|---|---|---|
| 🇰🇷 Korean | ko | Namo-v1-Korean | 97.3% |
| 🇹🇷 Turkish | tr | Namo-v1-Turkish | 96.8% |
| 🇯🇵 Japanese | ja | Namo-v1-Japanese | 93.5% |
| Show 20 More... | |||
To see all available models for different languages, along with their benchmarks and accuracy, please visit our Hugging Face models page.
3. Adaptive End-of-Utterance (EOU) Handling
The Adaptive EOU mode dynamically adjusts the speech-wait timeout based on the confidence scores. This ensures that the agent waits longer when the user is hesitant and responds faster when the user's intent is clear, creating a more natural conversational flow.
You can configure this by setting the eou_config in your pipeline options:
pipeline = Pipeline(
# ... other config
eou_config=EOUConfig(
mode='ADAPTIVE', # or 'DEFAULT'
min_max_speech_wait_timeout=[0.5, 0.8] # Min 0.5s, Max 0.8s wait
)
)
Configuration Parameters
| Parameter | Type | Description |
|---|---|---|
mode | str | • DEFAULT: Uses a fixed timeout value. • ADAPTIVE: Dynamically adjusts timeout based on confidence scores. |
min_max_speech_wait_timeout | list[float] | Defines the minimum and maximum wait time (in seconds) |
Example
| User Input | Agent Reaction | Wait Time | Example |
|---|---|---|---|
| Mode = DEFAULT Speaks clearly | Responds immediately | ~0.5s | “Book a meeting for tomorrow at 10.” |
| Mode = DEFAULT Pauses or hesitates mid-sentence | Waits slightly longer | ~0.8s | “Book a meeting for… um… tomorrow…” |
| Mode = ADAPTIVE | Adjusts based on speech clarity | Scaled between min/max | “Remind me to call… uh… John later.” |
4. Interruption Detection (VAD + STT)
Interruption Detection controls when the system should treat user speech as an intentional interruption. It evaluates both voice activity and recognized speech content to avoid triggering interruptions from short noises, filler words, or background audio. The agent only stops or responds when the user clearly intends to speak.
Configuration Example (HYBRID mode)
pipeline = Pipeline(
# ... other config
interrupt_config=InterruptConfig(
mode="HYBRID",
interrupt_min_duration=0.2, # 200ms of continuous speech
interrupt_min_words=2, # At least 2 words recognized
)
)
VAD_ONLY mode
pipeline = Pipeline(
# ... other config
interrupt_config=InterruptConfig(
mode="VAD_ONLY",
interrupt_min_duration=0.2, # 200ms of continuous speech
)
)
STT_ONLY mode
pipeline = Pipeline(
# ... other config
interrupt_config=InterruptConfig(
mode="STT_ONLY",
interrupt_min_words=2, # At least 2 words recognized
)
)
Configuration Parameters
| Parameter | Type | Description |
|---|---|---|
mode | str | • HYBRID : Combines VAD and STT. Requires both audio detection and recognized words to trigger an interruption. • VAD_ONLY : Uses only raw speech activity detection. Faster but may be triggered by background noise. • STT_ONLY : Relies only on recognized words from the transcript. Slower but ensures speech is intelligible. |
interrupt_min_duration | float | Minimum duration (in seconds) of continuous speech required to trigger interruption. |
interrupt_min_words | int | Minimum number of words that must be recognized (used in HYBRID and STT_ONLY modes). |
5. False-Interruption Recovery
The False-Interruption Recovery feature detects accidental or brief user noises and allows the agent to automatically resume speaking when interruptions are not genuine.
Configuration Example
pipeline = Pipeline(
# ... other config
interrupt_config=InterruptConfig(
false_interrupt_pause_duration=2.0, # Wait 2 seconds to confirm interruption
resume_on_false_interrupt=True, # Auto-resume if interruption is brief
)
)
Configuration Parameters
| Parameter | Type | Description |
|---|---|---|
false_interrupt_pause_duration | float | Duration (in seconds) to wait after detecting an interruption before considering it false. If the user doesn't continue speaking within this time, the interruption is considered accidental and the agent resumes. |
resume_on_false_interrupt | bool | If True, the agent will automatically resume speaking after detecting a false interruption. If False, the agent will remain paused even after brief interruptions. |
Pipeline Integration
Cascade Mode
Combine VAD with a turn detector on an STT → LLM → TTS pipeline:
- Inference
- Local Models
from videosdk.agents import Pipeline
from videosdk.agents.plugins import SileroVAD
from videosdk.agents.inference import NamoTurnDetectorV1
pipeline = Pipeline(
stt=your_stt_provider,
llm=your_llm_provider,
tts=your_tts_provider,
vad=SileroVAD(threshold=0.5),
turn_detector=NamoTurnDetectorV1(language="en", threshold=0.7),
)
from videosdk.agents import Pipeline
from videosdk.agents.plugins import SileroVAD, NamoTurnDetectorV1, pre_download_namo_turn_v1_model
pre_download_namo_turn_v1_model(language="en")
pipeline = Pipeline(
stt=your_stt_provider,
llm=your_llm_provider,
tts=your_tts_provider,
vad=SileroVAD(threshold=0.5),
turn_detector=NamoTurnDetectorV1(language="en", threshold=0.7),
)
Realtime Mode
Providers like OpenAI Realtime include server-side VAD and turn detection - external VAD and turn detectors are not required.
from videosdk.agents.plugins import OpenAIRealtime, OpenAIRealtimeConfig
from videosdk.agents import Pipeline
from openai.types.beta.realtime.session import TurnDetection
model = OpenAIRealtime(
model="gpt-realtime-2025-08-28",
config=OpenAIRealtimeConfig(
voice="shimmer",
modalities=["audio"],
turn_detection=TurnDetection(
type="server_vad",
threshold=0.5,
prefix_padding_ms=300,
silence_duration_ms=500,
),
),
)
pipeline = Pipeline(llm=model)
See OpenAI Realtime for full configuration options.
Example Implementation
Here’s a complete example showing Namo in a conversational agent.
from videosdk.agents import Agent, Pipeline, AgentSession
from videosdk.agents.plugins import SileroVAD, NamoTurnDetectorV1, pre_download_namo_turn_v1_model
from your_providers import your_stt_provider, your_llm_provider, your_tts_provider
class ConversationalAgent(Agent):
def __init__(self):
super().__init__(
instructions="You are a helpful assistant that waits for users to finish speaking before responding."
)
async def on_enter(self):
await self.session.say("Hello! I'm listening and will respond when you're ready.")
# 1. Pre-download the model to ensure fast startup
pre_download_namo_turn_v1_model(language="en")
# 2. Set up the pipeline with Namo for intelligent turn detection
pipeline = Pipeline(
stt=your_stt_provider,
llm=your_llm_provider,
tts=your_tts_provider,
vad=SileroVAD(threshold=0.5),
turn_detector=NamoTurnDetectorV1(language="en", threshold=0.7)
)
# 3. Create and start the session
session = AgentSession(agent=ConversationalAgent(), pipeline=pipeline)
# ... connect to your call transport
Examples - Try It Yourself
Got a Question? ![]() Ask us on discord
Ask us on discord

